
Pushing the Exoplanet Frontier with Deep Learning
 This summer I was invited to take part in the 2018 NASA Frontier Development Lab, along with a small team including Michele Sasdelli (University of Adelaide), and a pair of planetary scientists, Megan Ansdel (University of California at Berkeley) and Hugh Osborn (Laboratoire d’Astrophysique de Marseille).
Our team composed of both machine learning and planetary scientists, was challenged over the course of 8 weeks to combine our expert knowledge in order to improve the methods behind one of the most exciting frontiers of science: exoplanet discovery.
This summer I was invited to take part in the 2018 NASA Frontier Development Lab, along with a small team including Michele Sasdelli (University of Adelaide), and a pair of planetary scientists, Megan Ansdel (University of California at Berkeley) and Hugh Osborn (Laboratoire d’Astrophysique de Marseille).
Our team composed of both machine learning and planetary scientists, was challenged over the course of 8 weeks to combine our expert knowledge in order to improve the methods behind one of the most exciting frontiers of science: exoplanet discovery.
Here I discuss some of the challenges of applying machine learning to real-world scientific data, in particular noisy and sparse periodic time-series data.
Exoplanets
Our knowledge of exoplanets, or planets that exist outside our Solar System, has advanced drastically over the last few decades. In fact, until relatively recently one could have called exoplanets a theoretical concept. The first confirmed detection of a real exoplanet wasn’t until 1992 (Wolszczan et al. 1992), and even by 2004 only about a hundred exoplanets had been detected. This all changed with the launch of the Kepler space telescope in 2009 (Borucki et al. 2010). Since then, thousands of exoplanets have been detected with the ``transit” method (i.e., detecting an exoplanet by observing the drop in brightness of a star as the orbiting exoplanet crosses our line-or-sight to the star). This year (2018) a new but related space telescope was launched — the Transiting Exoplanet Survey Satellite (TESS) (Ricker et al. 2014). TESS, which also uses the transit method, will concentrate on finding exoplanets closer to Earth and around brighter stars than Kepler allowed, which will be important for follow-up observations necessary to help us learn more details about these exoplanets, such as their compositions and atmospheres.
TESS is already collecting new data with the potential to improve our knowledge of exoplanets, but there is a bottleneck to accessing this knowledge: humans. Each candidate planet identified by TESS must be confirmed by a scientist with follow-up observations from the ground, making it vital that these planet candidates be as reliable as possible, meaning that false positives must be minimized. At the same time, we must avoid missing real planets and minimize the false negatives.
The Kepler/TESS Pipeline
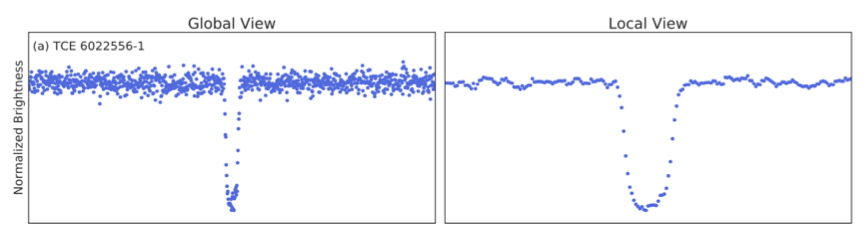
The raw data returned by a space telescope (i.e. Kepler/TESS) is essentially a very noisy, low-framerate video of a patch of the sky. For both Kepler and TESS, the data is a set of Target Pixel Files (TPFs), which are small (e.g. \(11 \times 11\) pixels) image frames roughly centered on the target stars, collected at a regular time interval over a given amount of time — every 2 minutes over 27 days for TESS. From these TPFs, the pipeline extracts time-series photometry of the target stars, called a “light curve”, which is essentially the 1D signal of the brightness of a star over time. The pipeline then must remove the systematic and random noise introduced by the instrument, as well as real stellar phenomena that can look similar to noisy exoplanet transit signatures. Only then can the pipeline search for the exoplanet transit signals — the characteristic drop in light when an exoplanet passes in front of its star (see fig. 1). This is no easy task, and a team at the NASA Ames Research Center has spent the greater part of a decade creating a pipeline to do all this for the Kepler data (Jenkins, et al. 2017), and is now also applying using it to process the new TESS data.
Challenges of the Kepler/TESS Exoplanet Datasets
The challenges present in the detection and classification of exoplanets are different than those typically seen in typical supervised machine learning problems. The quality and completeness of the “ground truth” is limited, being both noisy and intrinsically incomplete. Only the already discovered exoplanets are labelled and a large number of undiscovered planets are present in the data, sometimes incorrectly labelled as false negatives. Those planets that are labelled are biased towards the easier planets to detect — that is large planets. The nature of the TESS mission requires a quick “response time” in order to follow-up the most promising planets with other instruments without wasting limited telescope time and resources.
Transit signals are periodic dips in the light curves, but these are often near the noise floor of the data. Without the pipeline’s removal of systematic noise, transit signals are rarely apparent at all. Transit signals are also extremely sparse however, the occultation of the star due to the planet lasts only a very small fraction of the period and, depending on the planet’s orbital period, this might occur only a handful of times. What makes it possible to observe the transit signals at all is the high precision of the period of the dips, allowing the signals to be folded, averaged over the planetary period. The planetary period is unknown a priori, and must be exhaustively searched. All of these characteristics of the signals make the problem challenging, and different from problems typically solved with machine learning methods.
Learning Approaches
Lightcurves
Recently a deep learning approach to exoplanet classification from detection candidate light curves output by the Kepler pipeline was proposed (Shallue, et al. 2018). A CNN is trained on the light curves folded by the candidate period. Our main approach was to expand upon their work by incorporating more domain knowledge, and extending the method to the TESS dataset which is quite different than that of Kepler. We also addressed the severe class imbalance present in TESS — few candidates are labelled as planets vs. non-planets – by using mini-batch class balancing. Our approach improved in both performance and efficiency over that of (Shallue, et al. 2018). We also tried approaches of folding the candidate light curves on an exhaustive range of possible periods, avoiding the need for the pipeline’s detection.
Target Pixel Files
In a more ambitious on-going approach, we attempt to train on the raw TPF images, bypassing the Kepler/TESS pipeline. With the intrinsic systematic noise, and given the sparsity and low signal-to-noise ratio, we have found a very challenging dataset to train with however. A typical TESS TPF time series has dimensions 11\(\times\)11\(\times\)19815 and there may be as few as two transits. It is clear that novel machine learning approaches may be required to learn to classify exoplanets in the face of extremely sparse periodic signals.
Conclusion
In exoplanet detection, many of the challenges we encountered were typical of applying machine learning to any real-world problem, such as class imbalance and noisy labels. However, the problems we encountered in trying to learn from the raw TPF images highlighted real-world data that is not well addressed by current machine learning methods. In particular learning sparse periodic signals with a low signal-to-noise ratio, and in the presence of strong systematic noise is challenging.
For more information, view our recent presentation on the work we did over the summer, or see the FDL exoplanets challenge website.
Acknowledgments
I’d like to thank the whole TESS team at SETI/NASA who were a massive help and proposed this challenge, in particular Jeffery Smith, Jon Jenkins and Douglas Caldwell. I’d also like to thank the NASA Frontier Development Lab organizers and mentors for giving us this unique opportunity. And finally I thank our challenge’s industry partners: Google Cloud and Kx Systems, in particular Google Cloud’s generous donation of compute resources without the support of which our work would not have been possible.
Leave a Comment
Your email address will not be published. Required fields are marked *